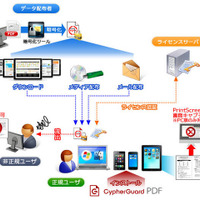
不正なPDFファイルが利用する検出回避手法
ブロードバンド
セキュリティ
注目記事
-

10G光回線導入レポ
-
iOSデバイスでPDFドキュメント漏えいを防止するASPサービス
-

Google、Android 4.4をNexus 7/Nexus 10向けに提供開始……Nexus 4には「近日中」
/
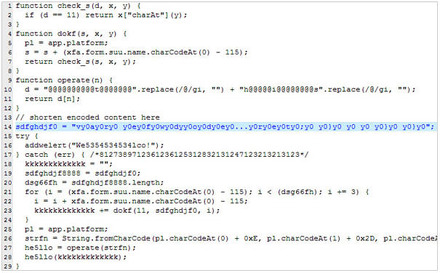
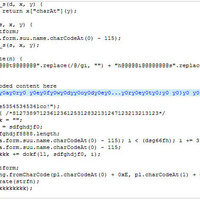
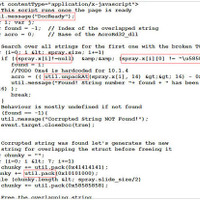
脆弱性を利用するPDFファイルの多くは、何らかの形で埋め込まれたJavaScriptを利用する。これにより、一般的なJavaScriptを利用した回避や難読化の手法がPDFファイルでも利用可能になる。たとえば、文字列の差し替えや例外処理「try-catch」、メソッド「fromCharCode」のループなど、すべての手法を利用できる。また、InfoObject 内の符号化されたプロパティ「Content」と関数「Function Name」、JavaScriptランタイム、フィールド属性とスコープ内の関数なども検出回避に利用される。
同社では、name属性により制御される異なる名前空間内で実行された JavaScriptのコードを確認している。これは、ツールを使用した解析を難しくすることがある。また、関数「eval」内で変数を変更することで、Adobe Readerでは実行されるが、他のJavaScriptエンジンでは実行されずエラーを表示し、不正なコードの解析を阻む手法も確認している。同社では、今後JavaScriptランタイムの確認と変数のスコープの変更の 2つの手法がさらに広く利用されると予想している。これらは、サイバー犯罪者たちによる検出回避への最新の試みを表すとしている。
不正なPDFファイルが利用する検出回避手法を徹底検証(トレンドマイクロ)
《吉澤亨史@ScanNetSecurity》

特集
この記事の写真
/