【富士通フォーラム2010(Vol.25)】縮退時間を大幅短縮、仮想化環境における業務継続性を向上
エンタープライズ
ハードウェア
注目記事








/
このソリューションの特長は、ブレードサーバ+VMware HA(High Availability)を単純に組み合わせただけの構成よりも、業務停止リスクを軽減できる点と、サーバ故障時に仮想サーバが縮退状態となる時間を短縮できる点にある。
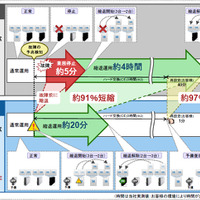
VMware HAの機能を使う場合、サーバ故障時は約5分間の業務停止が発生し、さらに縮退運用中のハードウェア交換および再設定に約4時間かかってしまい、この間、業務の応答レスポンスの低下等が懸念される。これに対して、RCVEを組み合わせる場合は、ブレードサーバがもつメモリやCPUなどの“故障予兆検知機能”を有効活用することで、故障が発生する前に仮想サーバを無停止で業務退避させることができ、また予備機を使うことにより約20分の縮退期間で自動復旧できるという。
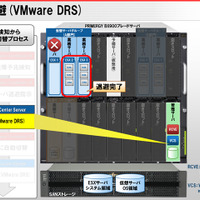
デモ環境は、仮想サーバがブレードサーバ「PRIMERGY BX900」および仮想化ソフトウェア「VMware vSphere4」、SANストレージが「ETERNUS DX60」エントリーディスクアレイで、仮想サーバのシステム領域はSANストレージ上にあるというディスクレスSANブートの運用形態。また、管理サーバにはRCVEおよび仮想環境の管理ソフトウェア「VMware vCenter Server」(以下、VCS)が搭載されている。
故障の予兆検知から自動復旧までのデモの流れは次のとおり。まず、RCVEがメモリ故障の予兆を検知すると、VCSに対して仮想サーバの退避指示を出す。すると仮想サーバの退避が完了し、メモリ故障の予兆が検知されたサーバを停止する。次にRCVEは、停止したサーバを予備機に切り替え、さらにVCSと連携して仮想サーバの再配置を行う、というもの。
サーバ統合やクラウド環境で基盤となる仮想化環境では、1台に複数の業務が集約されるため、ひとたびサーバ故障が発生すると広範の業務に影響が及ぶ。現時点では、サーバ故障予兆の検知確率は2割程度との話であるが、こうした停止リスクを未然に防ぐ仕組みは、ビジネス機会の損失回避や業務継続性の確保という意味で今後も期待されるであろう。また、HAクラスタにおける縮退時間の短縮は、CPUのマルチコア化やメモリ容量の拡大が進んで集約効率が拡大していくなか、業務の安定稼働を担保していくうえで、有用な機能と言えそうだ。
さらに、当デモではサーバ故障交換後に必須となるFCスイッチやSANストレージの事後処理が1クリックで完了するところも紹介されていた。従来の手動操作では32手順、約40分かかっていたということから、設定ミスによる手戻りの可能性などを考慮すれば、運用現場の負担は大きく軽減しそうだ。
富士通では、こうした仮想化環境での運用負担軽減機能を運用現場(SE)の声を数多く聞きながら実装しているという。また市村氏は、今後も仮想化ソフトウェアとうまく連携しながら、継続的に進化させていくと説明した。
《柏木由美子》
特集
この記事の写真
/