【テクニカルレポート】しゃべってコンシェルにおける質問応答技術……NTT技術ジャーナル
エンタープライズ
モバイルBIZ
注目記事
-

10G光回線導入レポ
-

ドコモとパイオニア、「しゃべってコンシェル」の自動車向け応用技術を共同開発
-

ドコモ、「電話帳」と「spモードメール」をクラウド化……SNS連携も用意、「しゃべってコンシェル」も機能拡張
/
検索型質問応答
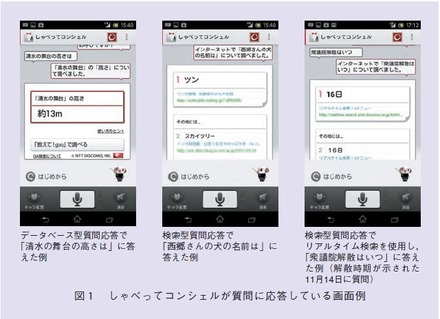
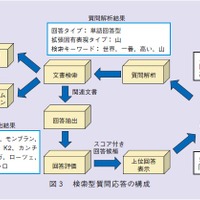
データベース型質問応答で回答が見つからない場合は検索型質問応答が実行されます.検索型質問応答では,質問解析,文書検索,回答抽出,回答評価の4つのステップによって,インターネットから,質問の回答を探します.図3は検索型質問応答の構成です.
(1) 質問解析
質問解析では,質問の「回答タイプ」を判定します.具体的には,まず単語で回答する「単語回答型」か,理由,方法,定義,評判など,文章で回答する「文章回答型」かを判定します.学校のテストでいえば,設問が穴埋め問題か,記述式かを判定しているのと似ています.そして単語回答型であれば,さらに単語がどの固有表現タイプであれば良いかを判定します.固有表現とは,固有名詞,時間,数値を指す表現の総称で,固有表現タイプとは,固有表現を類型化したとき,そのどれにあてはまるのかを示すものです.固有表現タイプの判定は,答えるべき単語がどんなものであれば良いかを絞り込む作業にあたります.
質問応答では,固有表現タイプとして8つのタイプ(人名,地名,組織名,固有物名,日付,時間,金額,割合)を用いることが一般的です.しかし,8タイプでは粗すぎて,答えるべき単語をうまく絞り込めない可能性があります.
そこで私たちは,拡張固有表現(3)と呼ばれるものを参考にし,100を超える拡張固有表現タイプを用いて,単語のタイプを絞り込むことにしました.例えば,「世界で一番高い山は?」では「山」,「黒澤明の代表作は?」であれば「映画」という拡張固有表現タイプであると判定し,回答すべき単語が山の名前や映画の名前であるというところまで絞り込みます.
単語回答型・文章回答型の判定や,拡張固有表現タイプの判定を高精度に行うことは,質問の表現が多様なことから,簡単ではありません.そこで私たちは,データベース型質問応答のときと同様,大量の事例を準備し,機械学習の手法を用いることで,高精度な判定を実現しました.この学習には,質問中の単語が持つ意味的な情報を利用することが不可欠です.そのために,NTT研究所の成果である意味情報が付与された大規模な辞書(4)を最大限活用しています.
なお,質問解析では回答タイプの判定に加え,次段の文書検索で用いる検索キーワードも抽出します.例えば,「世界で一番高い山は?」であれば,形態素解析の結果から,「世界」「一番」「高い」「山」といった単語を検索キーワードとして抽出します.
(2) 文書検索
文書検索では,検索キーワードを用いてインターネットを検索し,関連する文書を取得します.検索には,基本的に一般的なWeb検索エンジンを用いますが,今まさに起こっているような最新の情報については,Web検索エンジンでは見つからないことがあります.そこで,リアルタイム判定という機構を導入し,最新の情報についての質問であると判断される場合には,検索先をリアルタイム検索(Twitterのツイートの検索)に切り替えます.
リアルタイム判定は,直近を示す「今日」「現在」「昨日」といった単語が質問に含まれているかだけでなく,日々指す対象が変わる単語(例えば,「先発」や「ゲスト」)が含まれているか,また,インターネット上で急に出現頻度が増えたような話題語が含まれているかなどに基づいて行います.この機構により,「今日のメダリストは?」「○○番組のゲストは?」「ノーベル賞を取ったのは誰?」(ノーベル賞が話題語だとします)といった質問について,最新の情報を基にした回答を提示することができます.
(3) 回答抽出
回答抽出では,検索された文書から回答タイプに合致した回答候補を抽出します.ここでは,回答タイプが単語回答型の場合について説明します.
単語回答型では,拡張固有表現タイプに合致する単語を回答候補として文書から抽出します.例えば,「世界で一番高い山は?」の場合,文書から「山の名前」をすべて抽出します.
私たちは,拡張固有表現タイプのそれぞれについて,文書から回答候補を抽出する抽出器を,機械学習の手法で構築しました.具体的には,拡張固有表現の個所をラベル付けした文章を大量に準備し,単語系列が特定の拡張固有表現タイプであると判断する基準を学習しました.今回,100を超える拡張固有表現タイプを扱うことから,100を超える抽出器を構築しました.「山の名前」の抽出器もその1つです.なお,ここで学習に用いた拡張固有表現のデータは,日本語では最大規模のものです.
学習された抽出器は高精度ですが,学習データに含まれない状況では何も抽出できないという問題が残ります.そこで別途,拡張固有表現の辞書を整備し,抽出器が見逃してしまいそうな回答候補も発見できるようにしました.この辞書には100万を超える単語がその拡張固有表現タイプとともに載っており,山の名前だけでも数千あります.抽出器とこの辞書を併用することで,文書に含まれる拡張固有表現の網羅的な抽出を実現することができました.
(4) 回答評価
回答評価は,回答候補に正解らしさの点数を与え,順序付けを行います.しゃべってコンシェルでは1位の回答候補が読み上げられるため,できるだけ1位に正解を持ってくることが重要です.
質問応答では,回答候補の周りに多くの検索キーワードが見つかる場合,正解になりやすいという経験則があり,多くの質問応答システムはこれに則って点数付けを行います.しかし,例外も多く,精度が伸び悩むという問題がありました.
そこで私たちはここでも機械学習を用い,高精度なランキングを実現しました.具体的には,周辺文脈がどのような状況において,ある回答候補が正解になるかという基準を,大量の事例から学習しました.回答候補には,この基準に照らし合わせた,正解らしさを表すスコアが付与されます.最終的に,回答候補はスコアでランキングされ,上位の候補が画面上に表示されます.
今後の展開
ここでは,2012年6月にリリースされた,しゃべってコンシェルにおけるQ&A機能について解説しました.言語処理,特に機械学習をフル活用して,人間が質問に答える過程を真似て答えている様子が分かっていただけたのではないかと思います.
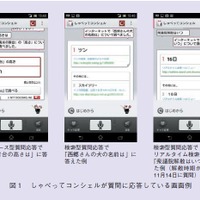
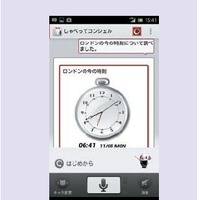
今回はデータベース型質問応答と検索型質問応答について説明しましたが,最近の取り組みとして,プログラム型質問応答も追加しました.これは質問に答えるために,何らかのロジックを駆動するタイプの質問に対応するためのものです,例えば,「ロンドンは今何時?」の答えは,データベースを検索しても,インターネットを検索しても見つかりません.世界時計の情報を参照し,その時刻情報を抽出するロジックを呼び出す必要があります.図4はプログラム型で質問に答えている画面の例です.プログラム型質問応答は,世界時計のほか,カレンダー,電卓,単位変換などにも対応しています.
質問応答の回答精度はまだまだ改善の余地があると考えていますし,今後も改善していきたいと思っています.また,文章回答型の質問についてはすべてに答えられるわけではありません.例えば,理由を聞く質問には答えられません.今後は,回答できる質問の幅も拡充していきたいと考えています.
■参考文献
(1)吉村:“しゃべってコンシェルと言語処理,”情処学研報,2012-SLP-93,pp.1-6,2012.
(2)磯崎・東中・永田・加藤・奥村(監修):“質問応答システム,”コロナ社,2009.
(3)S. Sekine,K. Sudo, and C. Nobata: “Extended named entity hierarchy,”LREC2002,Canary Islands,Spain,May 2002.
(4) 池原・宮崎・白井・横尾・中岩・小倉・大山・林:“日本語語彙大系,”岩波書店,1997.
◆著者紹介(敬称略)
吉村 健/内田 渉/東中 電一郎/貞光 九月
※本記事は日本電信電話(NTT)が発行する「NTT技術ジャーナル誌 Vol.254,No.2 pp.56-59,2013」の転載記事である
*「しゃべってコンシェル」は株式会社NTTドコモの登録商標です.
《RBB TODAY》
特集
この記事の写真
/