【連載・視点】ビッグデータ収集から解析まで一手に行う注目株……トレジャーデータ
エンタープライズ
企業
注目記事





/
創業者は日本人3名。ビックデータの収集、保存、解析を一手に行うクラウドサービスを提供しており、保存されているデータ量も2014年1月には3兆件に膨らむ予定だ。提供されるサービスは「スターター」「スタンダード」「プレミアム」「カスタム」に大別され、たとえば小・中規模の企業向けで投資対効果を短期間で得ることができるというスタンダードプランの場合、月額3000ドル(保存データは年150億件で、クエリー実行数は無制限でCPUは8コア、サポートが含まれている。)といった具合で初期投資を抑えたスタートが可能になっている。これらサービスはクラウドサービスの月額課金が基本だ。
日本法人は2012年12月に設立され、今年5月に国内本格展開を発表した。現在国内顧客企業はクックパッドやGREE、スシロー、無印良品など名の知れたところを含め約40社となっている。
日本人がシリコンバレーに企業を設立し、その業務を国内に広げるということ自体が珍しいかもしれない。これには、CEOである芳川裕誠氏が三井ベンチャーズのメンバーとしてシリコンバレーいたということも影響しており、同社が短期間で注目を集めたのは、シリコンバレーの風土と無関係ではない。ファウンダー兼CTOの太田一樹氏は次のように話す。「エンジニア自体の質は米国も日本もそんなに変わりはない。しかし、日本はとにかく最初に利益を追求する。むこう(米国)では、早く市場をとることに注力する。スピード感というか、いかに流行らせるかというマインドが違う」と。そういうマインドを後押しする仕組みもあり、サービスをプロセス化してマーケットに大量に売るノウハウをもった人がたくさんいると話す。
同社のビジネス哲学の根底には、「データを入れてからアウトプットするまでの色々な障害を取り除き、簡単にしていこう」という思想がある。太田氏は「データのソースにアクセスして、色んなところからデータをひろってくるという作業がプロジェクト全体のなかで6~7割くらい時間がかかる。とにかく、使うのも運用するのもすごい難しいなと。もし、この部分のサービスをクラウド上で提供し、とにかく簡単にデータを掴みはじめることができ、かつアウトプットもすぐに出せるサービスがあれば皆使ってくれると思った」と話す。太田氏は前職在籍中にHadoopと出会い、2009年に「Hadoopユーザーグループジャパン」を設立しているが、同ユーザーグループは登録者が1700人を超え、昨年には1200人が参加するカンファレンスを実施した。そこのコミュニティーと話すなかで問題となっていたのが、やはりシステム構築の難しさだったという。確かに、現状ビッグデータに手を付けろと言われているエンジニアは多い。しかし、システム構築には莫大な費用がかかる。企業は何がアウトプットされるかわからないものにはコストをかけない。なおかつアウトプットに時間がかかるとなると、現場は手の出しようがない。それどころか社内には人材がおらず、様々なシステムを担当しているのが1人のエンジニアというところも少なくない。その点、データ収集から保存、解析までを任せることができ、クラウドで低コストでスタートできる同社のシステムは魅力的にうつる。
さらに太田氏は続ける。「確かに我々にはコンペティターも結構いる。しかし、多くがクラウド上ですごくパフォーマンスのでるデータベースができました、などという売り方をしてる。それは顧客にとってはあまり関心のあることではないし、30%速くなっただけで現状はあまり変わらない。実際、トータルのコストにもあまり響かない。確かに速いのはうれしいが、構築のところでどれくらい簡単にできるのかがクラウドサービスとしてキーポイントだ。いかにすぐ使いはじめることができ、価値をはやく感じられるか。そこが差別かポイントになる。ほかのプレイヤーは、そこがブレていると感じる」。
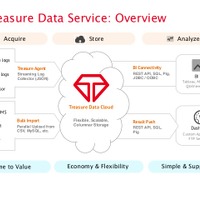
同社のシステムにはいくつかのポイントがある。まず、データの収集が高速である点だ。データ圧縮にも強い列志向型のデータベースを採用している。これはHadoopで利用されるHadoop Distributed File Sysytemよりもデータ保全、処理速度、圧縮面で優位性があるという。12月からは、さらにデータ集計・分析を素早く行うオプション「トレジャークエリーアクセラレーター」を発表してる。またログ収集基盤にはオープンソースのfluentdを企業のシステム向けに品質を安定化させたパッケージ「Tresure Agent」をツールとして提供している。fluentdは同社のソフトウェア・アーキテクトである古橋氏が開発。fluendにインプットされたログはJSONに変換されてアウトプットされる。これによりログを一括管理できる。
太田氏はデータの収集のところが一番難しいと話す。「ビックデータと言われているものは時系列データだ。今この瞬間も生成されていて、これからも溜り続けるというデータで、ウェブログ、アプリケーションログ、センサーログみたいなものがあるが、こういったものを効率的に収集する仕組みがなかった。非常に解析の進んでいる企業でも、ログファイルを1日に1回深夜のうちにサーバに集めるバッチを書いていたり……、結局それを確認できるのは1日後、というシステムがすごく多かった。そこをストリームで、リアルタイムにクラウドにアップしましょうエージェントを書くことで解決した」。fluentdはオープンソースとなっているが、オープンソースにした理由は、まずデータを収集している世の中にしなければいけないという思いがあったからだ。「fluentdのユーザーの5~10%でもトレジャーデータのお客さんになってくれれば、最終的には事業を拡大していけるんじゃないか?」と考えたという。
同社のシステムを使っている企業に回転寿司チェーン「スシロー」を運営するあきんどスシローがある。最初から回転台に流れている寿司を食べる客は少なく、実は7割がタッチパッドの注文画面から寿司を注文するという。スシローではこのタッチログを全てとり、どういう風に並べれば売り上げがアップするのかを分析。年間100億件のビックデータを処理している。
同社が次にやろうとしていることは、起業による問題点解決にすぐに対応しやすいように、ソリューションテンプレートを提供していくことだ。オンラインゲーム行動解析、マーケティングブランド解析、デジタル広告レポート&解析などを用意。設定済のBIレポーティングダッシュボードも提供していく。
《RBB TODAY》
特集
この記事の写真
/




